Unlocking Insights: Mastering Categorical Data Analysis in the Modern Data Era
Unlocking Insights: Mastering Categorical Data Analysis in the Modern Data Era
In an age where data flows in endless streams—each point a fragment of human behavior, market trends, or scientific observation—categorical data stands as a cornerstone of meaningful interpretation. Unlike numerical values that quantify change, categorical data reveals classifications: gender, industry sectors, survey responses, disease types, or preferred brands. Though often overlooked in favor of quantitative metrics, proper analysis of this data type unlocks patterns invisible to casual inspection.
Categorical data analysis transforms raw labels into actionable intelligence, empowering researchers, analysts, and decision-makers across fields ranging from healthcare to marketing and social sciences.
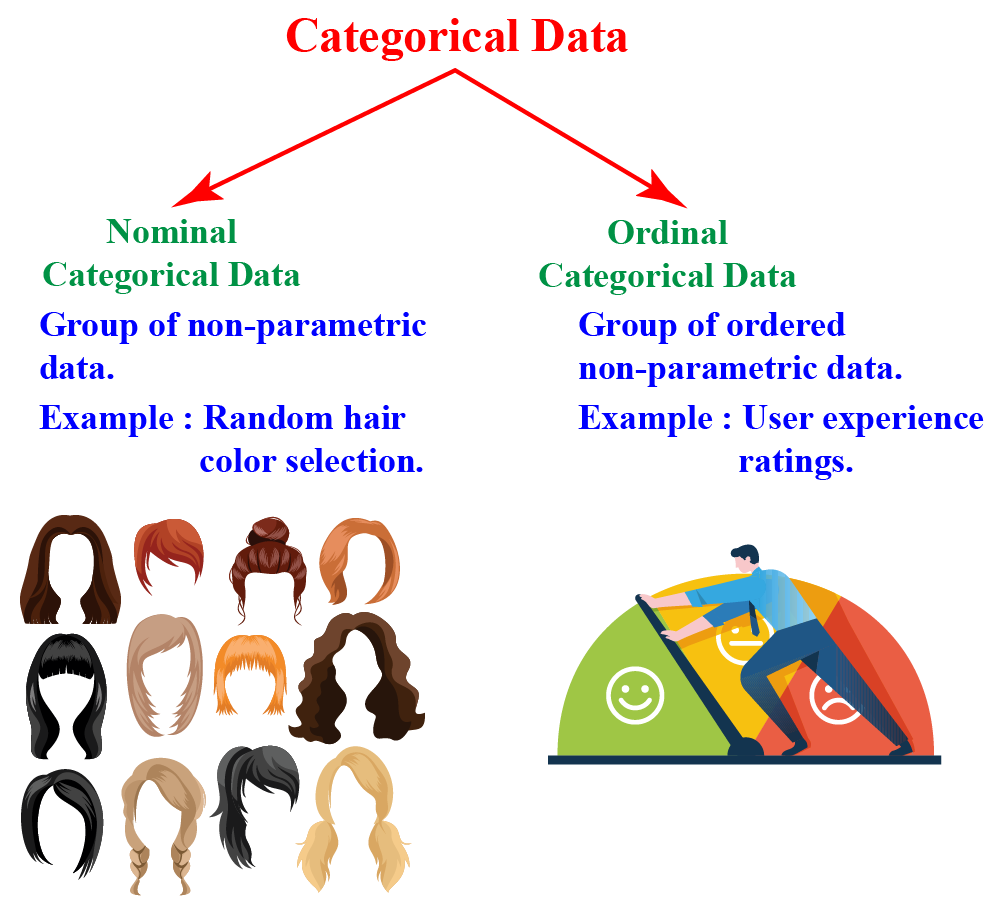
At its core, categorical data encompasses discrete categories or labels rather than continuous measurements. These categories may be nominal—where no inherent order exists, such as “red,” “blue,” or “diagnosis A vs.
B”—or ordinal, where hierarchy matters, like “low,” “medium,” and “high.” Understanding the nature of these categories is essential because it dictates which analytical tools apply. Unlike numerical data, which lends itself easily to averages and regression, categorical data demands specialized methods to capture relationships, associations, and distributions.
The Foundation of Categorical Data Analysis
Categorical data analysis centers on techniques designed to explore patterns among labels and their interdependencies. Key among these approaches is contingency table analysis, where frequency counts are organized in multi-dimensional tables to examine how categories relate.For example, a table cross-tabulating “smoker status” (yes/no) with “lung cancer diagnosis” (yes/no) reveals whether one condition correlates with another. Such cross-tabulations, grounded in statistical measures like the chi-square test, help determine whether observed associations are statistically significant or mere coincidence. Additionally, measures of association—such as Cramer’s V for nominal data or Spearman’s rank correlation for ordinal categories—quantify the strength and direction of relationships.
“These tools move beyond simple counts,” says Dr. Elena Martinez, a statistics professor at Stanford. “They allow analysts to test hypotheses about how categories interact, identify hidden dependencies, and assess the impact of one classification on another.”
Modern advances extend these foundational techniques through logistic regression, a powerful tool for modeling binary or multinomial categorical outcomes.
Unlike linear models suited for continuous results, logistic regression estimates probabilities that a category occurs, given predictor variables. For public health researchers, this means linking demographic categories—like age group or income level—with the likelihood of a medical outcome, enabling targeted interventions based on statistical evidence.
Real-World Applications: Translating Data into Decision Power
Consider the pharmaceutical industry, where categorical data analysis underpins clinical trial interpretation. In evaluating a new drug, researchers categorize patient responses—“improved,” “unchanged,” or “worsened”—to determine treatment efficacy.Because these outcomes are ordinal and discrete, analysts rely on models that account for their layered structure. “Without proper categorical modeling, critical signals in side effect reporting or treatment response might be flattened or misrepresented,” explains Dr. Raj Patel, a clinical data scientist.
Marketers deploy similar logic when analyzing customer feedback. A survey might ask respondents to select preferred brand from a list of five competitors. Using chi-square tests, analysts determine if loyalty strongly aligns with demographic segments—revealing, for instance, that younger consumers consistently favor eco-friendly brands.
This granular insight fuels personalized marketing and product development, turning raw categorical input into strategic advantage. In social policy, categorical data drives evaluation of equity initiatives. Government agencies track categories like “ethnicity,” “household income,” and “access to education,” using logistic regression to assess disparities and measure program impact.
“Data doesn’t speak for equity—analysis does,” emphasizes policy analyst Maria Chen. “By rigorously analyzing categorical outcomes, we uncover systemic gaps that remain hidden in aggregated statistics.”
Each application illustrates a fundamental principle: categorical data analysis transforms qualitative observations into quantified narratives, grounded in statistical rigor. Without this discipline, the rich information embedded in labels—gender, preference, diagnosis, sector—remains untapped potential.
Key Challenges and Best Practices
Despite its power, categorical data analysis presents unique challenges.Low-frequency categories—such as “rare disease types” or niche consumer preferences—can distort results, leading to unstable estimates. Analysts combat this through techniques like category aggregation or penalized modeling, balancing detail with statistical reliability.
Another hurdle arises when categories are resource-intensive to define, such as in sociocultural surveys where labels depend on subjective interpretation.
Clear operational definitions and pilot testing ensure consistency, preserving data integrity. “Ambiguity in classification undermines credibility,” warns Dr. Lena Wu, a data ethics expert.
“Transparency in how categories are created and coded is non-negotiable.” Best practices demand careful data preparation: verifying completeness, addressing missing values thoughtfully, and validating assumptions behind chosen models. Cross-validation and sensitivity analysis further strengthen conclusions, guarding against overfitting or confirmation bias. Ultimately, effective categorical analysis is as much an art of precision as it is a science of statistics.
The Future of Categorical Data Insight
As artificial intelligence and machine learning mature, their integration with traditional categorical analysis promises transformative potential. Natural language processing, for example, extracts and categorizes vast textual datasets—customer reviews, medical notes, policy documents—enabling automated theme detection at scale. When combined with probabilistic models, this allows nuanced understanding of how language and categories shape behavior and outcomes.Moreover, the growing emphasis on explainable AI recognizes that models relying on categorical logic must



Related Post

LMZhemma Samuelsson: Din Kompletta Guide to Mastering the Art of Abundance

Kanye West’s Latest Album Unveiled: Tracklist Analysis Reveals Artistic Evolution and Sonic Boldness

Aubry Wyatt: A Rising Star Burning Bright in the Entertainment Spotlight

Decoding "Knicks In 6" Meaning on TikTok: How Knick Players’ 6-Second Clips Converged with Fan Culture